

This post is a continuation of a singular topic: managing data science projects at an enterprise scale. In the first article, I laid out the 7 key factors (reproduced below) and focused on the first four. Just to refresh your memory, those factors are:
- Clearly define your goals and success criteria (yes, they’re two different things)
- Give your data science team time to succeed
- Redefine your use case as a machine learning problem statement
- Figure out what it would take to solve a problem without using machine learning
- Understand your correct ratio of data engineers to data scientists
- Architect with CI/CD in mind from the beginning
- Leverage data science code for data pipelining in production
Part 2 will focus on the latter three. So let’s jump into it!

5. Understand the correct ratio of data engineers to data scientists
Not all data scientists are created equally!
Some data science (DS) folks are born out of the fire that is data engineering, others are specialist PHD-holding gurus. Each has their own strengths and weaknesses, but all of them will have to learn how to manipulate data. To ease the burden on them and your systems, you’ll need some dedicated people to help them get the data they need when they need it. This is especially important if your DS types are relatively new to your organization and don’t know their way around the data landscape. Bring in some seasoned data engineers and your timeline will come down incredibly. It helps if they have some experience working with DS teams since a lot of data science requires data in a very strict predictable (pun intended) format that lends itself to feature engineering.
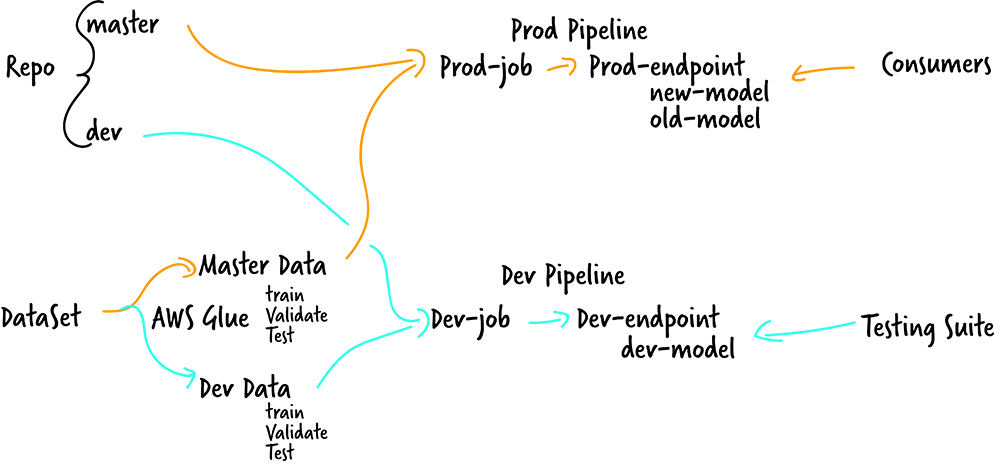
6. Architect with CI/CD in mind from the beginning
The background of this recommendation is outside the scope of this article, but I plan on doing a follow up that elaborates on this one. Data pipelines will have to be built to support the model that goes into production, but unlike batch reporting, machine language (ML) use cases tend to target real-time needs. Even near-real-time models pose a challenge for engineers. Worse is when data scientists create models that have a shifting feature set based on the most recent data (think about how you would handle “Most Active Customers in the past 30 days” as a feature input to a model).
Go back to our previous example about product recommendation. Wouldn’t you want your model to incorporate the most up to date reviews and customer attributes? Of course, this all depends on the nature of your industry: business-to-consumer (B2C) marketing is much more real-time than say pipeline routing where the majority of contracts are negotiated long in advance. How about dealing with new customers? Will a model need to make recommendations the same day for a new customer? Understanding how your data changes over time is key to building sustainable pipelines to support model development and refinement.

7. Leverage data science code for data pipelining in production
I saved the best for last; and this isn’t the first nor the last time I will write about this: leverage the work your data science team has already done. DS work is similar to data analytics in that both teams readily need access to multiple data sources, time to massage data, and direction on business objectives; yet differ when we look at the process. DS is an R&D activity. Your DS team shouldn’t be fixated on delivering day-to-day operational metrics. DS teams are like wild horses: they need room to stretch their legs and run. And like a wild horse, if you follow it long enough, you’ll find water.
Your DS team will likely spend a lot of time using applications like Jupyter, R Studio, or PyCharm. The latter of which provides some benefits with more GUI tools for CI/CD and version control. Using a more “notebook” style environment to import, transform, and model data is more appealing for the DS team because these tools operate as a GUI interface on top of a run-time language: they can selectively execute small blocks of code, check the results, iterate changes quickly, then move on. This makes the DS development process much smoother… for development.
Once a model is trained, productionizing notebook code can be a nightmare. We need to productionize this code because the work the DS team did to build the model involved a lot of data prep (bringing in data from multiple sources, joins, filters, etc..). Why all of this needs to be captured and recreated for production pipelines is beyond the scope of this post. I will list some reasons though
- The feature set used to train the model will be needed when an inference is requested for any supervised learning models
- The calculations to obtain numerical features (10-day averages, running totals, etc..) might be tailored to fit the specific use case (net sales can mean ANYTHING)
- Writing these features to persistent storage in your warehouse might cause governance issues if these calculations are not properly documented with the data
Access to the code base where the DS team keeps their code under revision (if you aren’t using some sort of version control shame on you) will be necessary. Also, don’t keep your engineering team in the dark until it’s ready to go to production (they need sunlight and fresh water to grow). Stand-ups should include engineering representatives as well as data scientists. These incremental updates will help everyone code towards a common goal: automating production delivery.
That concludes this two-part series about managing data science projects. I hope you all found something useful – feel free to quote me. Follow me on LinkedIn and stay up-to-date on the latest from Sullexis. Sullexis is a data-centric, client-obsessed consulting company. Our four practices work together to deliver the highest quality of service