

Machine learning model…. Cloud deployment strategies…. BANG ZOOM WOW!! OK now that I have your attention, let’s talk shop!
Deploying an ML model to enhance the quality of your company’s analytics is going to take some effort:
- clean data
- clearly defined objectives
- Strong project management
So many articles have been written on the first two bullet points (garbage in , garbage out) I figured I would convey some of my experience in the third: managing a machine learning project.
Effective management is second only to the accuracy of the model
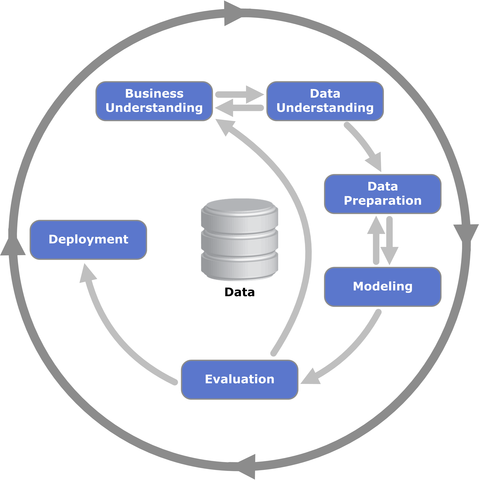
If you just want a strong model, the CRISP-DM process will suffice in guiding your team to that desired goal. But,
- If you want this to be the first of many projects, and
- you want your users to actually use the model and
- you want a manageable, scalable solution
Then I have a few suggestions for you. I’ve put together a list of my top recommendations to help managers along their journey to machine learning mastery. Those recommendations, in no particular order:
- Clearly define your goals and success criteria (yes, they’re two different things)
- Give your data science team time to succeed
- Redefine your use case as a machine learning problem statement
- Figure out what it would take to solve a problem without using machine learning
- Understand your correct ratio of data engineers to data scientists
- Architect with CI/CD in mind from the beginning
- Leverage data science code for data pipelining in production
1. Clearly define your goals and success criteria
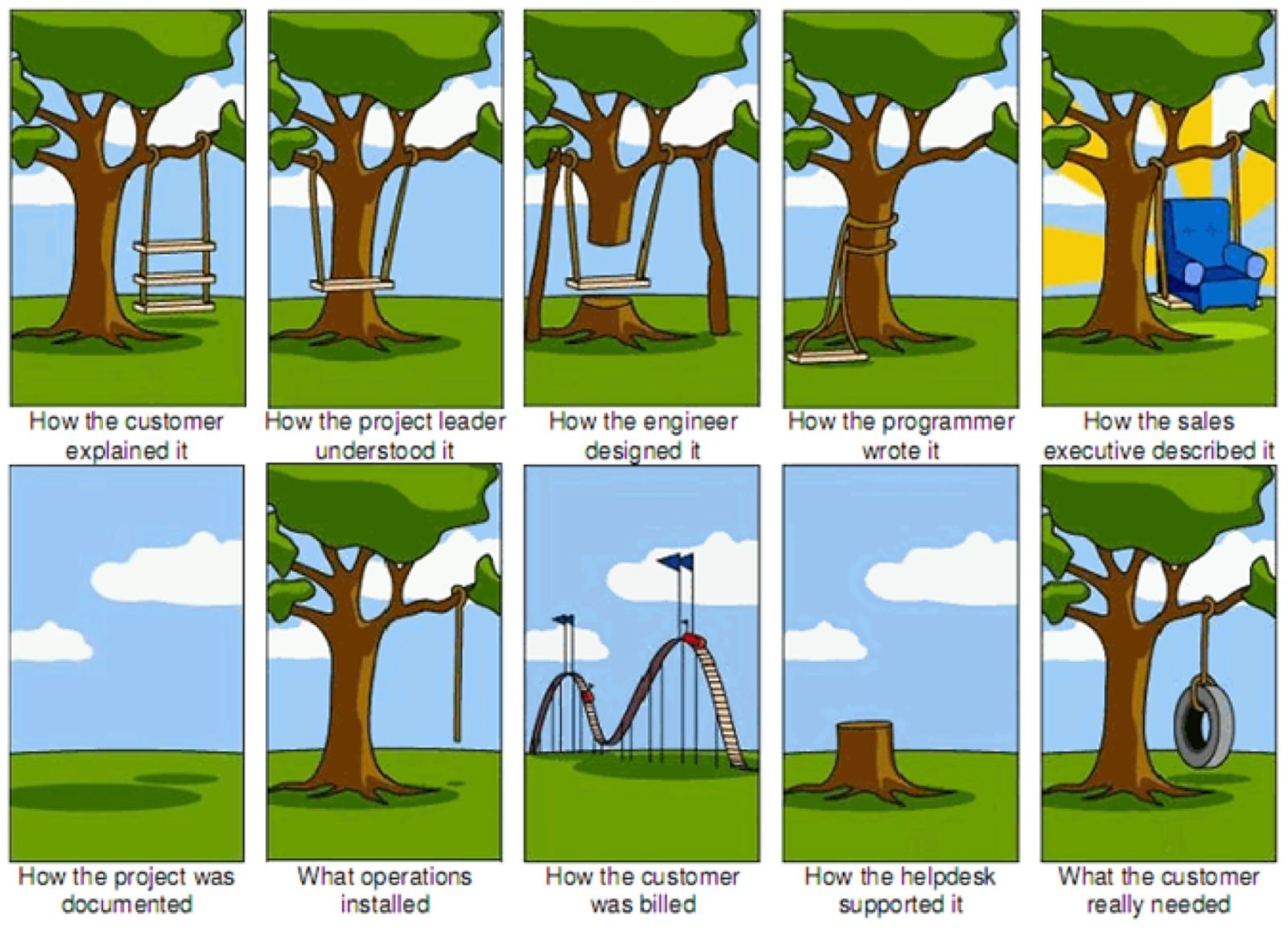
Sometimes companies view data science as a pure research department. Companies like Google and Amazon can afford to burn millions of dollars on research every year, but in the corporate world – more often than not – people will want to see value in the work. Yes, I agree it’s ok to fail, but failing to maintain a departmental budget from projects that yield no value is not. My suggestion is to start small and identify a quick win.
Lay out your goals. Ask yourself:
- What are we trying to achieve?
- What questions/problems do we want to answer/solve?
Try and answer these questions at a high level first (e.g.determine naturally occurring customer segments, predict equipment failures with greater accuracy), then ask yourself, why? Why is it important to determine customer segments? Why bother predicting equipment failures? This seems like an obvious step but it’s one that is often overlooked. Data scientists tend to work a theory before deciding if it’s a good investment of time.
Remember:
- Before digging a trench, figure out why you’re digging.
- If you cannot come up with a good reason for digging until you’ve dug a hole, odds are no one else needs that hole
You can have the best model in the world that no one ever needed. Going through the process laid out above can help avoid the frustration of having no one appreciate the hard work that goes into digging a hole.
Now lay out your success criteria (SC), which is defined as the metrics against which your goals will be measured. Determining the SC will be based on what’s driving your need for ML. For instance, if your company is looking for ways of increasing gross margin, your success criteria should be determined as a function of gross margin (e.g. we will be successful if the model can find 3% gross margin in lost deals)
2. Give your data science team time to succeed

This is an unpopular statement that no manager wants to hear: we cannot guarantee positive results. This is where managing expectations comes into play. Executive leadership needs to understand that data science projects require an initial investment of time and money. There are many ways to do this which go beyond the scope of this article, but here are some of the tactics that have helped:
- Take on smaller, non data science projects to keep the lights on while your DS team works towards a breakthrough
- Find someone in executive leadership to help champion your case
- Don’t over-invest in technology until you have a rock solid use case
- Perform pilot or POC projects before investing months of development time (think before you dig!)

3. Redefine your use case as a machine learning problem statement
This is the fun part, and part we are all familiar with: translating business requirements into technical. First, frame your problem in terms of a problem that needs to be solved. Doing this will not only ensure you heard your users correctly but really helps highlight the value proposition (or lack thereof) in their request. After doing so, you have an analytics use case. Let’s take a simple classification problem as an example. If your users say, ‘we want to personalize product recommendations based on total sales, customer attributes, and like product reviews’ . In machine learning, I would reformulate this statement as “can we create a model that maximizes total sales based on customer attributes and like product reviews?” This statement doesn’t answer the question, but it’s a perfect lead into a conversation about which attributes will be used for a feature set in the model.

4. Figure out what it would take to solve a problem without using machine learning
This might seem like a no-brainer, but it’s a really big one. This point speaks to the practical issues that arise by not implementing the previous point. If you cannot reframe your use case into a machine learning problem statement, you might not have a problem that needs ML.
Have you ever implemented something new at your company? Something radically different from the status quo? If you have, you know there will always be nay-sayers and disbelievers. Odds are some of them are the same people you’re trying to convince to fund the project. I’ve seen ML projects stop dead in their tracks and turn into YART (yet another reporting task) because during a presentation, someone says, “that looks like it could have been done with 5 if/else statements” (We hate that guy). We’ve all been swept up in the excitement of using the brand new shiny technology stack; but ML is not a panacea to every problem.
Some quick questions to help sniff out potential ML poser use-cases:
- Can I deliver a solution (or part of the solution) deterministically?
- How long would it take to code a solution to the posed problem?
- Is there an out-of-the-box application that would work?
- Is someone else already doing this elsewhere in the company?
Take some time and diagram out the basic architecture of a solution like this. It might turn out that your use case can be delivered as a simple dashboard or a quick python script that spits out a one-time analysis. Don’t waste time with use cases that can be handled by the BI team; remember, your job is to help take your company/department to the next level of analytics greatness.
I hope you’ve enjoyed part one of this post. In the next post I will wrap up the 7 important factors, expanding on my favorite point: leveraging data science code for data pipelines in production!
Follow me on LinkedIn and stay up-to-date on the latest from Sullexis. Sullexis is a data-centric, client-obsessed consulting company. Our four practices work together to deliver the highest quality of service