

Now more than ever companies are relying on their big data and analytics to support innovation and digital transformation strategies. To meet this challenge, big data teams scale out on-prem Hadoop resources to create a unified data fabric, connecting all aspects of the business together. However, many Hadoop users struggle with complexity, imbalanced infrastructure, excessive maintenance overhead, and overall, unrealized value.
Elephants, Bees, and Whales, Oh My!
Let’s start with the basics: what is Hadoop? Hadoop provides a software framework for distributed storage and processing of big data using the MapReduce programming model. Basically, it’s a set of programs enabling multiple servers to coordinate and work together to solve a single problem. Out of the box, Hadoop is massively complex and reliant on heavy user configuration, requiring users to have a deep understanding of not only Hadoop but the underlying OS as well. Hadoop is made even more complex by the ecosystem tools. If you google Hadoop Ecosystem logos, it looks like someone dropped a zoo on top of a Home Depot. Confusing logos aside, Hadoop started out as a cheap data store and efficient batch ETL processing platform, but never managed to grow into a full-fledged data analytics platform. Many companies have tried to extract analytics value from Hadoop and failed because Hadoop was never really intended to be an analytics platform.

The Dark Side of Hadoop
Hadoop is a highly efficient storage platform, and great for running batch ETL processes, but so many companies saw Hadoop as the solution to the real problem big data brought with it: time-to-insight. Traditional ETL and RDBMS tools were not able to keep up with the terabytes of data being generated. Hadoop promised if all that data was centrally located in a distributed environment, all our analytics problems would be solved. Companies began pouring entire source systems and transaction logs into Hadoop, but quickly realized it wasn’t so simple. Building efficient data stores for querying was complex and end-users wishing to use that data needed to be intimately familiar with the underlying complexity in order to take advantage of the cluster’s computing power. Worse, all of that complexity demanded constant maintenance – nodes going down, services needing restart… Nothing seemed automated without a lot of custom scripting and programming.
Companies purchased Hadoop to match the growing needs of the business for ad-hoc queries against larger data sets. They wanted to tear down data silos but instead built complicated data swamps. The Hadoop ecosystem tools never evolved to be enterprise-friendly for the average business user to use and required highly skilled data engineers to performance tune every business query.
Enter the Cloud
I am not saying cloud providers have the panacea to all our problems, that would put me in the same group of people who praised Hadoop as the 2nd Coming. What I will say is public cloud providers have created an attractive alternative for customers still laboring over Hadoop on-prem.
Know Before You Buy
To be fair, cloud providers developed many of their big data-friendly services by listening to the complaints of Hadoop customers, so it makes sense why it’s such an attractive alternative to running Hadoop on-prem. Big data solutions needed to be scalable, provide massive amounts of computing power, and provide a convenient entry point for users of all data literacy to glean insight. To be fair, big data problems are still present:
- Data models still need to be optimized for a purpose
- Developers should be aware of operational limitations
- Deployed use cases need to be monitored and tuned over time
The difference is cloud services abstract the complex parts of those tasks away from the customer. No more cluster maintenance means little to no downtime. Query tools require more configuration than customization, saving tons of human capital down the road when something breaks. Monitoring and logging are not low-level Linux services writing text to a document; instead, web-based rules-driven dashboards help DevOps keep an eye on usage and error detection.
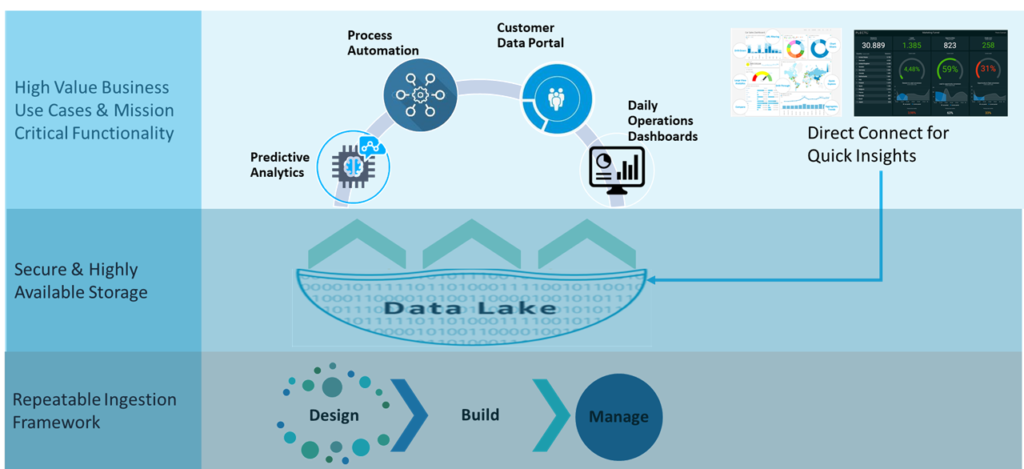
Don’t Go At It Alone
Like all technology stacks, cloud services don’t come without their negatives. There’s a learning curve for the cloud. While some of your Hadoop services will translate over and play well with a SaaS architecture, some will not. Understanding your cluster service layout, dependencies, and currently deployed use cases is imperative if you plan to make the shift to the cloud. Also, moving to the cloud means re-architecting at least some percentage of your on-prem solution. No matter what anyone tells you, lift and shift is only appealing upfront; a lift and shift implementation lacks the foresight needed to avoid overpaying for cloud resources, and possibly recreating the same problems that drove the migration. If you bring the same processes that weren’t solving the problem into a new environment, you’ve only compounded your problems.
Migrations might sound scary and daunting, but staying with a solution that isn’t working is just as dangerous. If you are considering making the switch to the cloud, Sullexis is here to help. Our Data Engineering Practice has years of experience working with Hadoop and helping clients re-invent their data lakes in the cloud.