
Data management technologies are a dime a dozen and are improving at an ever-increasing rate. How does one determine how to transform data technologies such as cloud storage, data streaming, no-SQL technology, ML, and AI into an effective (and cost-saving) data management solution? How can one leverage the vast variety of open-source and product-based solutions to incorporate various data transformation solutions to provide data insights rapidly, repeatedly, and efficiently?
Data is Always…
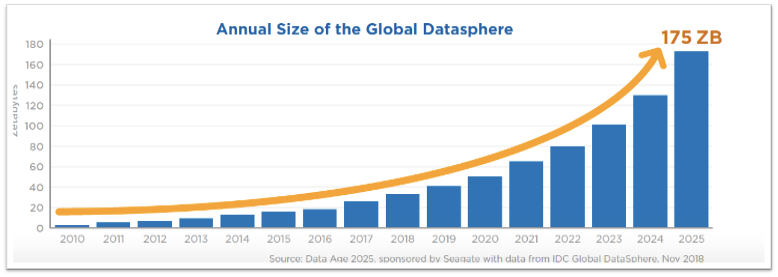
First, there needs to be the recognition that data is always growing, ever-changing, and will always need monitoring and maintenance. As our data continues to grow and expand, our abilities and capabilities to capture, store, and manage data need to continually scale and adapt. To reinforce this point, in the “Data Age 2025” study by the IDC Global DataSphere, they predict that by 2025 that almost 50% of all the world’s data will be housed in public cloud environments and that the size of the total amount of data around the world will be 175 zettabytes (yes, that’s with a ‘z’)! To picture this, 175 ZB is equivalent to watching Netflix’s entire catalog 525 million times! So what do we do to get ahead of this?
The Data Needs & Capabilities
In order to best use our data, we must understand what we are asking for our data to do for us. Too many times, people want to focus on technology to solve the problem versus sitting down and deciding what problems need to be solved. In other words, what are our “Data Needs”. In the same IDC Global DataSphere study, they separated out the fundamental data needs into three critical areas: Core, Edge, and Endpoint.
- Core – The data stores that house the data (public and private clouds, data centers, etc.)
- Edge – Where the data is moved, managed, and transformed (corporate offices, data gateways, cell towers, etc.)
- Endpoint – Where the data is created and/or utilized (People, vehicles, IoT, Mobile, API, Connected processes, etc.)
Once the data needs are defined, a prioritized approach to developing, executing, and deploying capabilities can be created. This provides a clear list of what needs to be done in terms of what data capabilities to provide based on the needs of your organization. Companies can leverage their data to adapt their products and services to better meet the needs of customers, optimize their infrastructure and operations, and increase their competitive advantages for better revenue generation.
Sullexis’ Reference Architecture
How does one architect a solution that takes into account the Data Needs and Capabilities? Make sure the architecture approach utilizes Sullexis’ Reference Architecture: Data Acquisition, Data Persistence (including Stream Data), and Data Analytics Offload.
- Data Acquisition – This section focuses on ingestion data from the sources and staging it for further data movement activities.
- Data Persistence (including Stream Data) – This layer organizes the data into topics/subjects, leveraging the power of the cloud platform, polyglot persistence (when needed), and/or data-as-a-service capabilities deployed as well real-time processing capabilities.
- Data Analytics Offload – This section allows the end-users to access the data in a variety of analytic, reporting, and/or monitoring tools based on their needs.
By building the solution in accordance with Sullexis’ Reference Architecture, there are several advantage gains that can be realized:
- Technology Agnostic – The Data Persistence & Streaming Data layer can leverage a variety of technologies (i.e. Mongo DB, InfluxDB, Kafka, AWS, Microsoft Azure, Confluent, Nifi, Apache Drill, etc.)
- Can scale as needed based on the data topics that are needed and can be managed in one secure platform
- Allows data acquisition teams to off-load reporting and data support and separates data acquisition/source environment to allow upgrades as needed with minimal impact downstream

Part 2 – Practical and Pragmatic Working Examples
In part 2 of the “Art of the Data Possible”, we will get to see a production deployed use case that shows the Sullexis Reference Architecture effectively executing, the data management capabilities leveraged, and the benefits realized by the business stakeholders. Stay tuned for part 2 to come out later this month. In the meantime…
How To Get Started?
Sullexis has developed the Reference Architecture approach for companies that are in all stages of their data management lifecycle. Whether your organization is managing across a myriad of legacy systems, data lakes, cloud platforms, or if you are looking to build a greenfield solution or your organization is somewhere in between with integrated public, private, structured, and unstructured data sources, Sullexis can help! By utilizing modern data transformation best practices, Sullexis can provide a data platform design and implementation plan to better manage Data analysis, Data Replication, Data Management, BI Tool Connectivity, Support, Scalability, Data Stream, and Cluster Monitoring, and Disaster Recovery/Failover.
Sullexis has many production-deployed examples and experience in leveraging your systems, solutions, and your existing people and skillset/resources to help you discover the art of the data possible in your organization. Ask us how and we will schedule a session to discuss a number of options to show you what is possible.