

Introduction to SageMaker
I’ve been working with AWS SageMaker for a while now and have enjoyed great success. Creating and tuning models, architecting pipelines to support both model development and real-time inference, and data lake formation have all been made easier in my opinion. AWS has proven to be an all encompassing solution for machine learning use cases, both batch and real-time, helping me decrease time to delivery.
Prior to my exposure to public cloud services, I spent a lot of time working in hadoop distributions to deliver the processing power and storage requirements for data lake construction, and utilized Docker to provide data science sandboxes running R studio or Jupyter notebook. The install/configuration time was a turn off to a lot of clients. We needed a more agile way to manage the data science team’s infrastructure.
I started working with AWS out of curiosity, but got my first AWS certification out of need. The project involved setting up a data science environment, which led me to AWS SageMaker
If you’re just interested in the solution architecture, skip ahead
Unboxing SageMaker
AWS Sagemaker is a fully-managed service providing development, training and hosting capabilities. While I focus on ML, SageMaker can be used for any AI related use case. The service was designed to keep the learning curve as low as possible, and remove a lot of traditional barriers related to data science. SageMaker is subdivided into 4 areas: Ground Truth, Notebooks, Training, and Inference.
Ground Truth
Ground Truth is an automated labeling service offered by AWS. In supervised learning algorithms, the machine expects the developer to provide labeled examples. In other words, if you want to train a model to detect some value or a variable X, then the user must provide to the training set examples where the value is non null for variable X. A model designed to categorize cars vs people on a picture of a busy road, won’t be able to figure out which group of pixels represent the car or the person. You have to provide that during the training. This is where Ground Truth comes in handy. If you plan on training your model with 9000 images, someone is going to have to go through each photo and tag the cars and the people, which can be time consuming. If you can afford it, AWS will farm out that work for you. Admittedly, the service is limited to image and pattern recognition, so if your data can be modeled in a 2 dimensional space, this will not be of much use.
Notebooks
Notebooks are the development arena you’ve always wanted but your company wouldn’t let you have. Spinning up a SageMaker Notebook provides the user with a fully functioning, internet connected, conda-fueled IDE. The user has the same capabilities as if deploying a local Jupyter instance. The instance is a Docker container so all your work will persist until you decide to delete your notebook instance. The Notebook can be used for data manipulation, algorithm selection, data analysis, creating and kicking off training jobs, and even deploying your newly trained model into production! But beware: AWS pay-as-you-go model is in effect and you’re charged by the hour. If you leave your Notebook instance running over night (even if no computations are taking place) you’re still being charged, which can easily turn into 100’s of dollars a month in unnecessary development costs.
Training
If you’re like me, you prefer to do everything in code, and that includes monitoring your training job with a callback from the Sagemaker Training API. But consider the case of a pilot or POC, when I’m working with a new service, every line of code I have to write diminishes the value since the point of a pilot or POC is to prove out some idea or technology, not see how easy it is to understand programming documentation. This is where AWS SageMaker shines. The service provides a robust set of monitoring and automation tools to help you track down past training jobs, gather metrics about not only the training but the algorithm implementation. This can be especially helpful if your choice of algorithm is a black box and you’d like to gain some understanding around configuration or feature weights.
Inference
I mentioned a notebook can be used to deploy a model into production. The inference section is where a user can view and further configure deployed models, Inferences can either be batch jobs or real-time. In the case of real-time, each model is hosted on an endpoint (which is a fancy word for docker instance) and each endpoint has a configuration. The endpoint configuration – amongst other things – links a model to an instance pre-configured to perfectly host a model of that algorithmic configuration. All of this is handled for you behind the scenes, which makes hosting your model in production a lot easier in terms of maintenance and infrastructure management.
A Repeatable Serverless Solution for Real-Time ML Use Cases
I want to share one of my go-to design patterns for deploying an ML use case, quickly, and cheaply. This is not a technical post, and in a later post I will share step by step instructions on how to set up the below architecture, but for now I want to review the architecture and talk a little bit about what makes it easy, especially when getting your first use case off the ground.
Generic Architecture
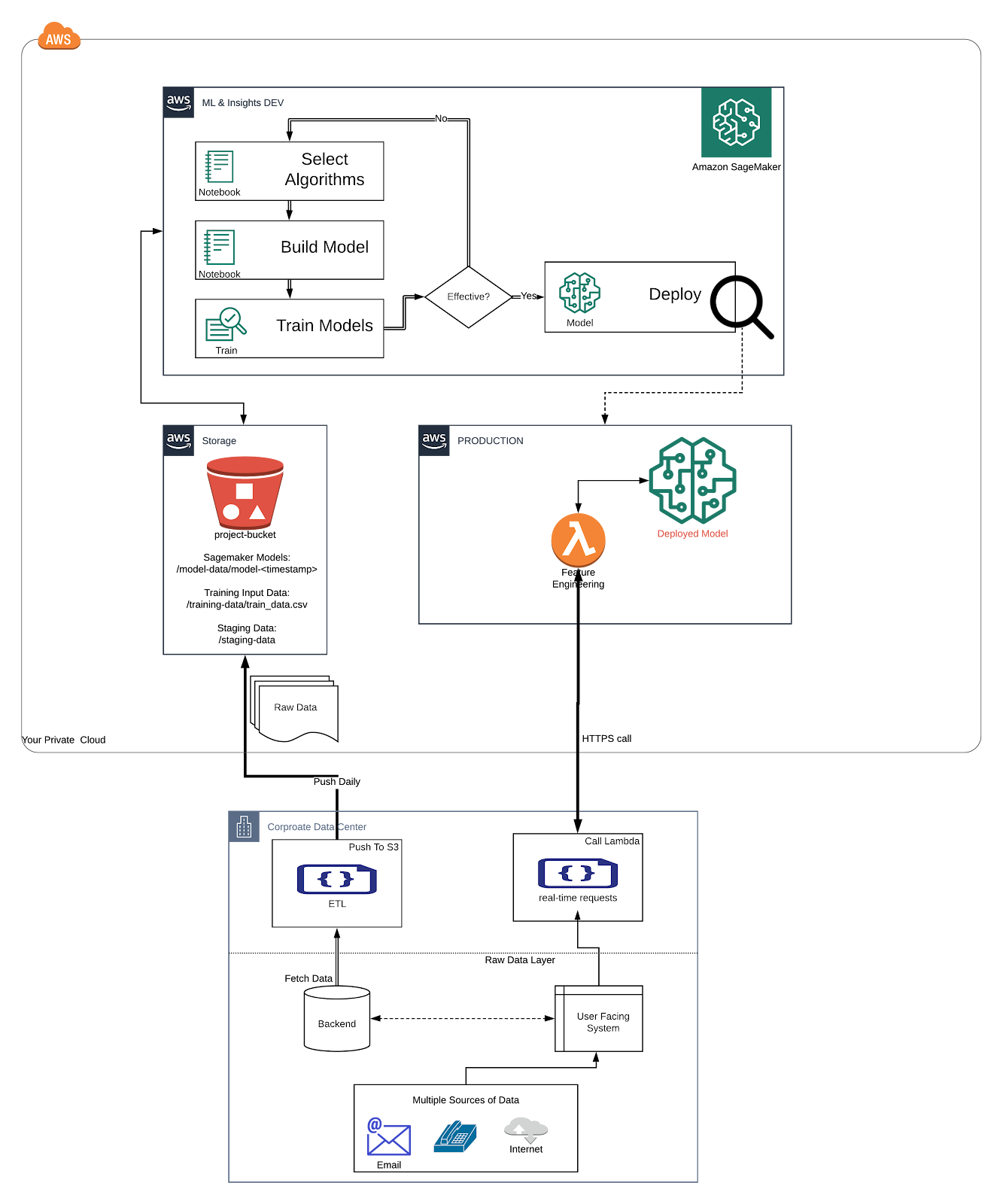
The overall architecture of a real-time ML use case requires 3 mandatory pieces:
- A SageMaker Endpoint: A working model, deployed in a managed Docker container that exposes the model logic to other AWS services
- A Lambda function: A managed service to parse the incoming request from the calling application and create the structure required by the model hosted on a SageMaker Endpoint
- Calling Application: Code (python, java, C# etc…) that places a call to your Lambda function and passes input necessary for the model to make an inference
On-Prem Pieces
I would recommend pushing or syncing data rather than pulling with a cloud service. Since this is serverless deployment, this gives you greater flexibility and programmatic control where some cloud services might run into barriers negotiating existing security barriers.
Remember this is about getting your first use case off the ground.
The word of the day here should be spefficiency (Speedy Efficiency).
- Write a quick python script to move data up to S3
- Choose python because it is popular with DS teams for data prep in SageMaker
- When productionizing the data flow, syncing changes to the model’s structure with your data pipelines will be easier to automate
- As a habit, when I deploy an analytics use case in the cloud with an on-prem piece, I publish the logs to CloudWatch. It can be a pain to manage a solution where you have to check multiple places when something goes wrong (something always goes wrong)
- The service API’s in AWS are extremely powerful: you shouldn’t waste time in the beginning designing fault-tolerant, formalized pipelines, because everything is likely to change during model development as the DS team refines ideas and theories based on newly discovered insights
SageMaker
A SageMaker endpoint provides access for other AWS services to call the model and receive inferences. The endpoint consists of a configuration and a trained model.
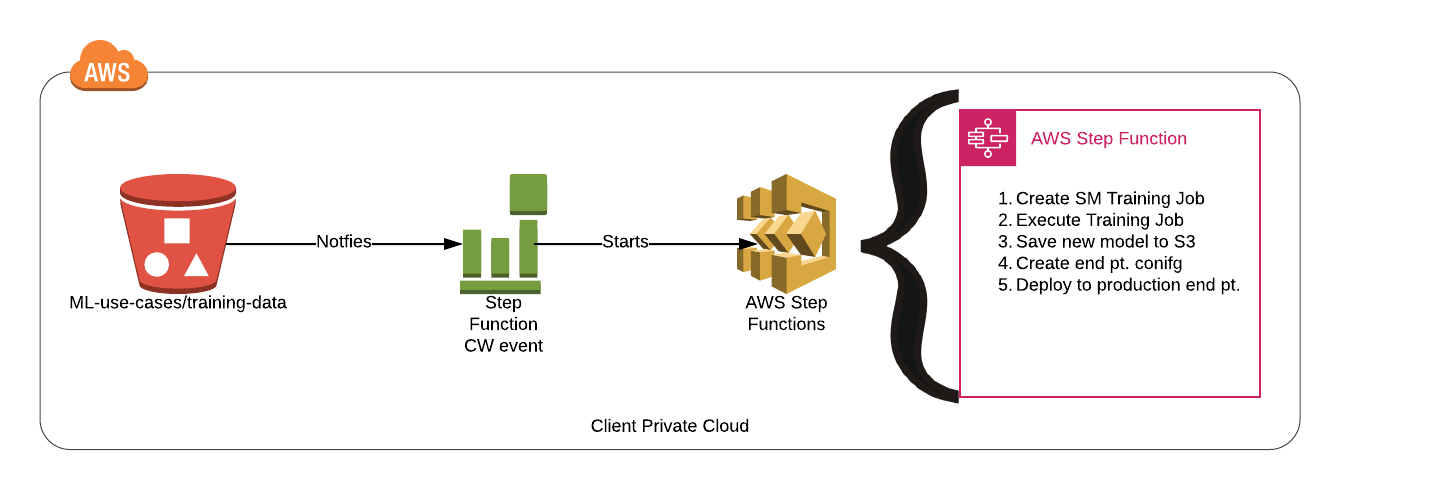
- In production, consider utilizing a workflow orchestrator like AWS Step Functions to automate pushing new models. It can handle popular deployment strategies including blue-green testing
Lambda
Since this is a real-time use case, AWS Glue and Batch won’t be adequate in meeting SLA. Lambda service runs your code, when needed, and scales nicely to use cases ranging from ecommerce websites with 100’s of thousands of hits per day to CRM systems requiring inference on new customers.
The lambda service serves as a middleman between the calling service and the SageMaker Endpoint. The Lambda receives the request from your on-prem system and turns that into a request the ML model can understand. Some helpful tips:
- The on-prem system requesting an inference rarely has all the data needed to make an inference, it’s best to pre-compute and store the results in S3 so your Lambda function can quickly read it in as needed
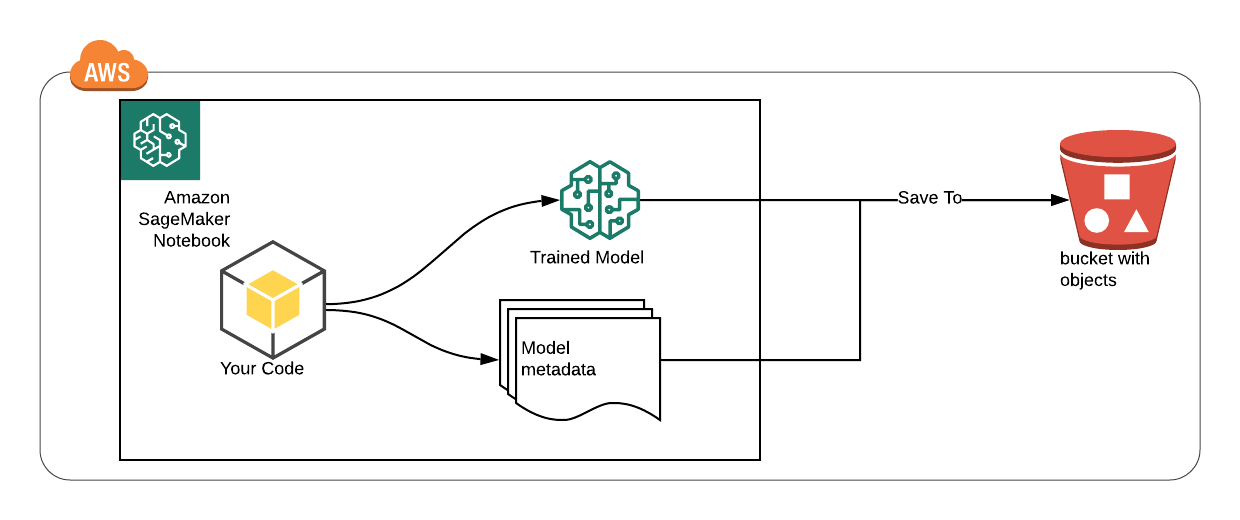
- Right before training your model, write the model’s metadata to S3 (column names, and types). The order is important as most algorithms use positional mapping and not column names during an analysis (think of a multidimensional array with no headers)
My hope is you’ve gained a little bit more information about AWS SageMaker and the convenience this service can bring to your IT organization. If you’re considering launching an ML project, reach out to us. You don’t have to navigate this new territory alone. Sullexis is here to help make your information useful!